Demystifying LLMs for Swift Developers: Part 1
June 21, 2025
When I first delved into large language models (LLMs), I often found the explanations perplexing. Many resources were tailored to those with a background in data science or Python—something I, like many Swift developers, didn’t possess. During my presentation at the One More Thing Conference Cupertino 2025, I chose a different approach. Instead of diving into the complexities of the transformer (often the toughest part to grasp), I focused on what happens before and after it. This approach simplifies understanding the entire system. If you’re a Swift developer exploring Apple’s open-source AI framework, MLX, or just curious about how LLMs function, you’re in the right place.
The Three Essential Files of an LLM
Before diving into the details of large language models (LLMs), it’s useful to first understand their basic components. By examining each part separately, you’ll gain a clearer picture of how they work together. Plus, if you’re interested in experimenting yourself, you’ll need to know where to find and use these files.
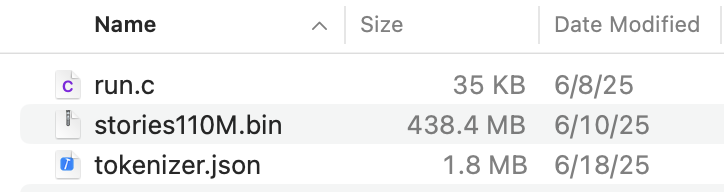
An LLM typically consists of three core files:
- The Inference Engine
This executable runs the model. We’ll explore this through Andrej Karpathy’s llama2.c project, which is a self-contained C application. Its core source file (run.c) is only about 35 kilobytes, highlighting its compactness. While simpler comparisons might mention its ability to fit in a vintage computer’s memory, what stands out is how few dependencies it has—using only standard C libraries like stdio and math. - The Tokenizer
Typically namedtokenizer.json, this file defines how text is broken into tokens—the basic units the model understands. Tokens might be whole words or fragments, such as prefixes or suffixes. For example, the word “Walkman” could be split into “walk” and “man.” The tokenizer also includes special tokens for unknown words and markers for text boundaries. The tokenizer file is part of the model, which you can download here. - The Model Weights
This is the largest file, containing the trained parameters of the model. It includes:- Embeddings: These act like GPS coordinates of tokens, mapping each token in a high-dimensional space. During training, the model clusters related words together, allowing it to understand context.
- Weights: These matrices are at the core of the model’s reasoning and generation capabilities, processing input and generating output.
It’s important to note that these files are static and read-only. Once trained, an LLM does not learn new information.
An LLM allows users to access its knowledge, stored in the model’s weights, using plain English or other trained languages. Unlike traditional software, you don’t need a coding language like SQL. Understanding these files provides insight into how an LLM functions during inference. Once you’re familiar with them, you’re ready to explore how they interconnect. In the following posts, we’ll delve deeper into how these components collaborate to power an LLM.